Patriks Data Lager Blogg
Detta är Patrik Lagers blogg med reflektioner, ideér och goda råd till alla som jobbar med Data warehouse och Big Data.
Blogginläggen är Patriks egna och behöver nödvändigtvis inte representera Top of Minds åsikter eller ståndpunkter i alla ämnen.

Inlägg
-
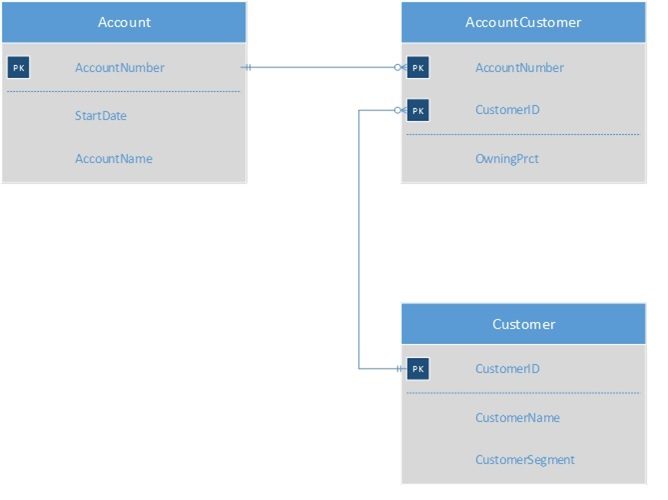
Musings on Data Modelling
2018-10-02 -
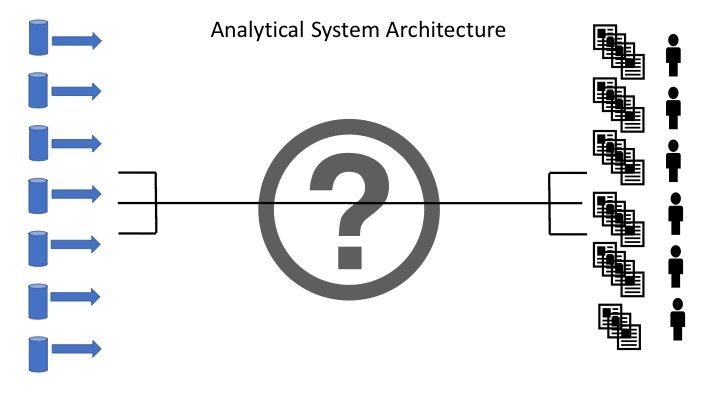
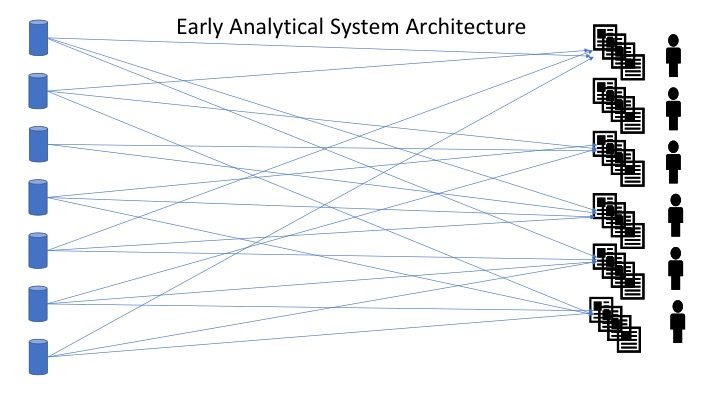
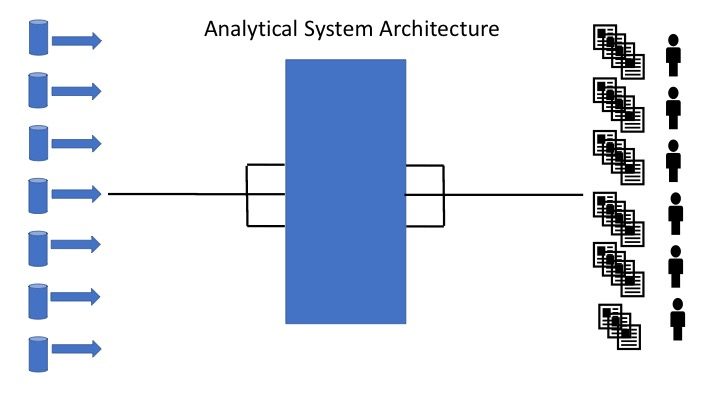
Thoughts on Architectural blue print
2018-09-06 -
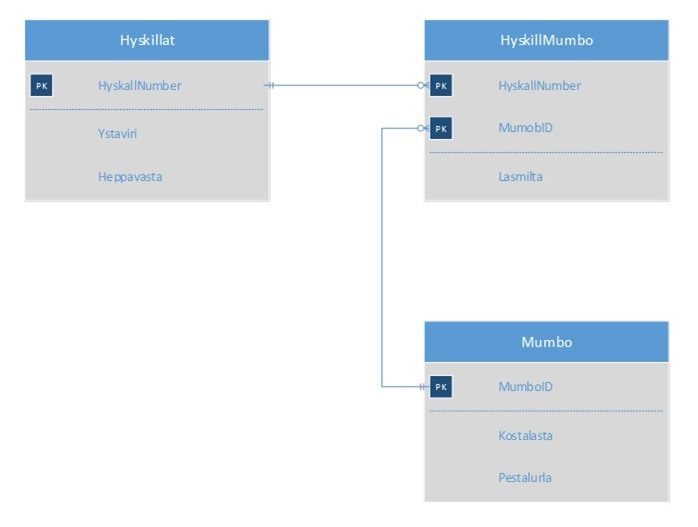
Ensemble Identifiers (Focal Theory)
2018-08-07

 Earlier this year had a wonderful time when I was on vacation in Barcelona. One of the things I visited was
Earlier this year had a wonderful time when I was on vacation in Barcelona. One of the things I visited was