
Analytical Systems architecture and design patterns – Part 1
This series of blog posts will discuss system architecture and design principles to build an analytical system with maintainability, scalability and longevity. Further on, discuss the details in the design principles to give the analytical system agility, reusability and robustness.
These principles have been learned and explored the hard way, through empirical experiments (building analytical systems) and observing the results over the last 40 years of what works and what does not work. To understand why the principles of architecture and design of an analytical system are what they are, we need to go back in history before we knew what we know today.
The Copy System
In the 70’s and 80’s the data systems got more and more common. They were built to support different operational processes in the business. Even at this time the business understood that in all that data that was gathered in these operational systems there was knowledge to be used to support decision making. So, they wanted to use that data to understand how the company was doing. One issue was that the operational systems where fully occupied to support the business process and any analytical query against it would ruin its operational performance.
The solution was to offload the operational system on to another platform. Just copy the tables/files every month or so to the other platform and someone could start running queries against the data without disturbing the operational system.
Once the knowledge was extracted out to of an operational systems data, more questions from the business started to appear and these questions could not always be answered by data from one operational system, so we needed to off load data from more operational systems, this was done into the same platform as the first system, just by copying each operational systems tables/files. So the Copy System came to be, the first analytical system.

Figure 1: The first Analytical System – The Copy System
Now there was a system that had data copied from multiple operational systems. The data was stored according to the operational systems data models.
Since the Copy Systems were very much an afterthought in the IT landscape and there were no good architectural design principles for how to build and maintain these systems, they often had big problems of handling change of requirements for queries and problem when the underlying systems, who’s data that was copied, changed. These problems would escalate as more systems was copied and more query requirements where implemented.
The Many to Many Challenge
What is the fundamental challenges of building these analytical systems then? It is that there are two sides in the system (Ingestion and Access) and they have a many to many relationships between them.
- Ingestion Area must handle
- Multiple information areas
- Multiple IT systems
- Multiple Data models
- Multiple local semantics
- Multiple local identifications
- Access area must handle
- Multiple user groups
- Multiple analytical/report requirements/use cases
- Multiple granularities
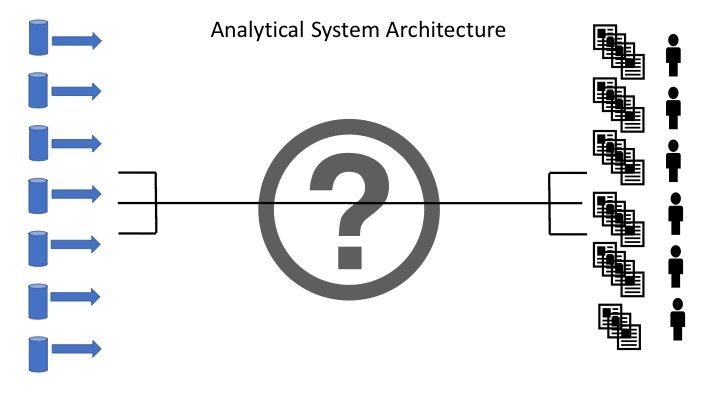
Figure 2: Analytical System Architecture – Many to Many dependencies
This is a major difference between building an operational system and an analytical system. An operational system supports specific business processes. These processes have clear steps on what they want to achieve. The input of data in clearly defined and the output is well defined. The number of use cases/scenario the system should support Is limited and the user group of the system is well defined and limited. On the other hand, an Analytical system has many different data sources and a lot of different user groups with a lot of different requirements to support multiple different processes.
This means that the analytical system does not know all the different requirements/use cases it will have to support in its life cycle. So how do you then design a system that does not know what requirements it is supposed to support?
In the early days (70’s, 80’s, 90’s) the architecture looked like this, or the lack of architectural design patterns made it look like this.
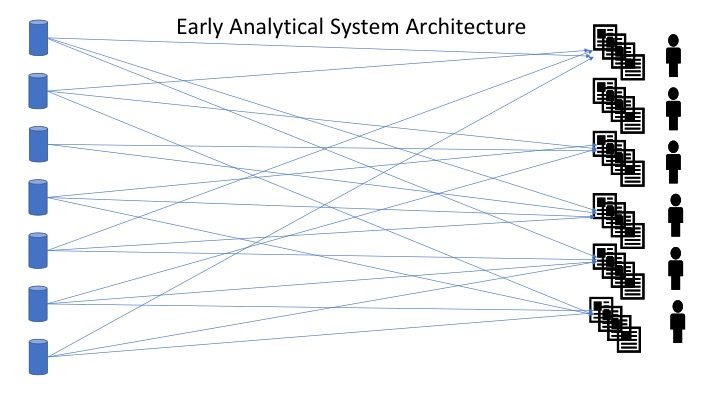
Figure 3: Early Analytical System Architecture and design
As we can see it is a mess of spaghetti lines with multiple dependencies on data and usage of data. Any time a new requirement/use case entered the analytical system, new lines of dependencies between users and data sources was created. This was of course not maintainable or scalable over time as new requirements and systems came in.
The Associative Component
So how do we handle these many to many relationships between Ingestion and access? We look how it is done in a data model, where we add an associative component when there is a many to many relationship. I have not seen it called that way any other place, but it is one way to describe what this componet in the architecture is meant to do – mitigate and handle many to many relationshipes between source data and user requirement.
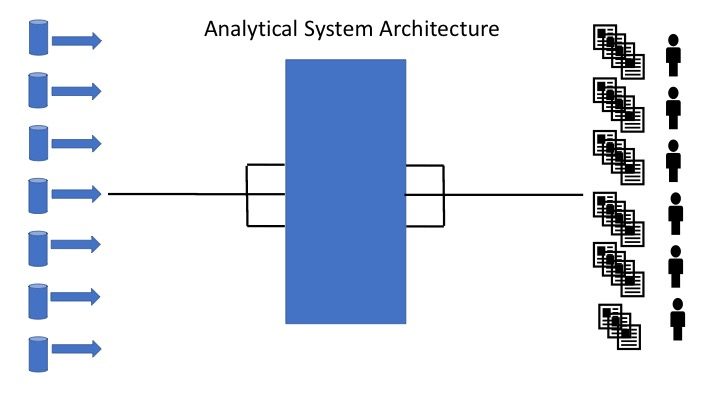
Figure 4: Analytical System Architecture – the associative component
Now the definition of that associative component is the important part on how to build an analytical system. Bill Inmon gave us that definition in the early 90’s and it still stands.
“a subject oriented, integrated, nonvolatile, time variant collection of data in support of management’s decisions”
In the next part of this blog series I will describe my view on what the definition means and why it is so important if you want to build an Analytical System that will be maintainable and scalable over a long-time frame.